Meeting 'minutes' fail to capture the gestalt of what happens during a meeting. Minutes can in principle capture the gist (depending on the skill of the editor/scribe), but are vulnerable to wide variation and even abuse by overzealous editors. Verbatim transcripts (if available) can be daunting in the amount of detail they yield, making it difficult to see the wood for the trees. We have already made some advances in the automatic analysis of meetings at a coarse-grained level (e.g. visualizing who dominated the broadcast and chat5 channels of a meeting). Our long-term research goal is to use FM in automating a more detailed 'caricature visualization' of meetings, indicating meeting phases, to improve the browsing and retrieval of specific video segments.
It is important to form an understanding of the 'transitional flow' of the meeting by marking the start and ending of related topics as meeting phases, e.g.:
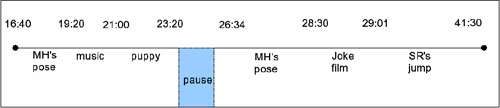
We have coded one meeting including animation students critiquing each other's work and have come up with the following emergent coding:

At step (1), we annotate the utterances with speech acts (labeling of topic and acts). At step (2), we apply the communication modeling to help us identify what may possibly be the focus at every turn-taking. At step (3), we mark the ending and beginning of the topics grouped together to form meeting phases. At step (4), we label the turn-taking from step (2) into acts. This is a meta-level of topic. These acts might explain what constitutes the basic characteristics of the meeting. At step (5), we group the meeting phases belonging to particular situation.
The lexical analysis of this meeting indicates that the open class words 'poses' (38 occurrences) and 'pose' (17 occurrences) are amongst the top hundred frequent words of the meeting transcript and are used over 200 times more frequently in the context of this animation discussion, when comparing their relative frequency to the general language in the British National Corpus. This indicates how to automatically detect the main theme of the meeting. Furthermore, we have identified emotion types and tokens occurring in the audio transcript of this meeting following (Ortony et al, 1988). The authors' cognitive classification of emotion types is cognitively associated to beliefs, goals and behaviour. In this meeting we have detected 95 words or collocations (out of 9,648 words in total included in the transcript) referring to 13 types of emotions out of 22 types in the theory, e.g.: the emotion 'LIKE' (43 occurrences) can be coupled with words such as 'awesome', 'cool', while the emotion 'DISLIKE' can be coupled with 'frowned at', 'don't like that' etc. Emotional words are more frequent in this kind of meeting, when compared to a moderated project meeting. Emotions such as 'anger', 'disappointment', 'love', 'sadness' and 'gratification' were detected only in the animation meeting, correlating with speech acts such as 'express concern', 'sharing fear', and 'wish'.
For more For more information, please contact:
Dr. Nik Nailah Binti Abdullah
National Institute of Informatics,
2-1-2 Hitotsubashi, Chiyoda-Ku,
Tokyo, Japan.





